
搜索结果: 16-30 共查到“知识库 人工智能”相关记录5329条 . 查询时间(1.171 秒)
基于IMOCS-BP神经网络的锂离子电池SOH估计
锂离子电池 健康状态 布谷鸟搜索算法 BP神经网络
2024/3/5
锂离子电池随着循环充放电次数的增长,其健康状态SOH(state-of-health)会随之发生一定程度的衰减。针对以上问题,设计了一种基于改进的多目标布谷鸟搜索IMOCS(improved multi-objective Cuckoo search)-BP神经网络的锂离子电池健康状态估计方法,在避免算法陷入局部最优的同时自适应改变布谷鸟搜索CS(Cuckoo search)算法更新概率和搜索步长...
近些年,联邦学习(Federated learning,FL)由于能够打破数据壁垒,实现孤岛数据价值变现,受到了工业界和学术界的广泛关注.然而,在实际工程应用中,联邦学习存在着数据隐私泄露和模型性能损失的问题.为此,首先对这两个问题进行数学描述与分析.然后,提出一种自适应模型聚合方案,该方案能够设定各参与者的Mini-batch值和自适应调整全局模型聚合间隔,旨在保证模型精度的同时,提高联邦学习训...
一种基于随机权神经网络的类增量学习与记忆融合方法
连续学习 灾难性遗忘 随机权神经网络 再可塑性启发
2024/1/16
连续学习(Continual learning,CL)多个任务的能力对于通用人工智能的发展至关重要.现有人工神经网络(Artificial neural networks,ANNs)在单一任务上具有出色表现,但在开放环境中依次面对不同任务时非常容易发生灾难性遗忘现象,即联结主义模型在学习新任务时会迅速地忘记旧任务。
针对实际中某种工况滚动轴承带标签振动数据获取困难,健康指标难以构建及寿命预测误差大的问题,提出一种基于无监督深度模型迁移的滚动轴承剩余使用寿命(Remaining useful life,RUL)预测方法.该方法首先对滚动轴承全寿命周期振动数据提取均方根(Root mean square,RMS)特征,并引入新的自下而上(Bottom-up,BUP)时间序列分割算法将特征序列分割为正常期、退化期和...
针对城市污水处理过程的非线性、不确定性以及非高斯等特点,提出一种数据驱动的溶解氧(Dissolved oxygen,DO)浓度在线自组织控制方法.首先,设计一种基于相关熵的自组织模糊神经网络控制器(Correntropy-based self-organizing fuzzy neural network,CSOFNN),采用相关熵与规则贡献度指标实现控制器结构与参数的自动构建或修剪。
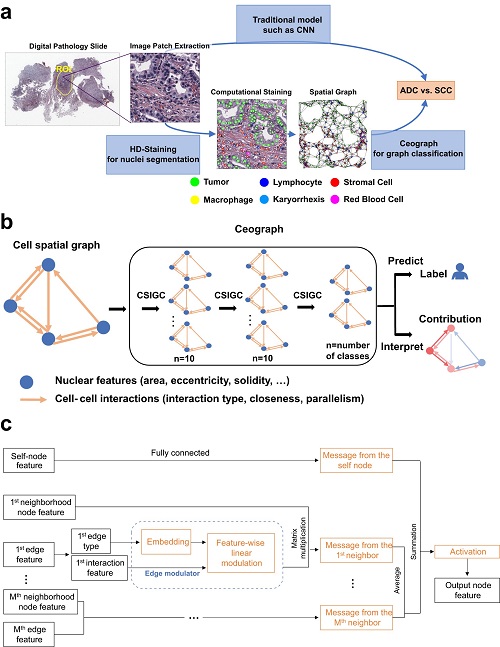
AI分析组织样本准确预测癌症结果(图)
AI分析 癌症 人工智能 鳞状细胞癌
2023/12/18
美国得克萨斯大学西南医学中心研究人员开发了一种新的人工智能(AI)模型,可分析组织样本中细胞的空间排列。2023年12月11日发表在《自然・通讯》上的这一创新方法,准确地预测了癌症患者的结果,标志着在利用AI进行癌症预后和个性化治疗策略方面取得了重大进展。
物理机制神经网络基于失效信息的自适应采样
物理机制 神经网络 失效信息 自适应采样
2023/12/13
Physics-informed neural networks (PINNs) have emerged as an effective technique for solving PDEs in a wide range of domains. It is noticed, however, that the performance of PINNs can vary dramatically...
唐铮等:生成式人工智能与新闻业:赋能、风险与前瞻
生成式 人工智能 新闻业
2024/1/2
生成式人工智能正在给新闻业带来前所未有的冲击。延续智能媒体的实践,生成式人工智能将通过其强大的内容生成能力助力新闻内容生产范式转换;倒逼从业者重构职业形态,迭代升级新闻传播业态,并以此最终重构人机关系的内涵,为新闻内容生产关系带来变化。这些冲击在进一步赋能传统新闻业,推动新闻业迈向强人工智能的同时,也带来了传播的信任危机、道德的伦理冲突和平台权力拓展的隐忧。为此,智能规范必须建立,机制监管亟待完善...
基于语义引导特征聚合的显著性目标检测网络
显著性目标检测 混合注意力 多层次融合 深度学习
2024/1/16
在显著性目标检测网络的设计中,U型结构使用广泛.但是在U型结构显著性检测方法中,普遍存在空间位置细节丢失和边缘难以细化的问题,针对这些问题,提出一种基于语义信息引导特征聚合的显著性目标检测网络,通过高效的特征聚合来获得精细的显著性图.该网络由混合注意力模块(Mixing attention module,MAM)、增大感受野模块(Enlarged receptive field module,ER...
高炉料面视频关键帧是视频中的中心气流稳定、清晰、无炉料及粉尘遮挡且特征明显的图像序列,对于及时获取炉内运行状态、指导炉顶布料操作具有重要的意义.然而,由于高炉内部恶劣的冶炼环境及布料的周期性和间歇性等特征,料面视频存在信息冗余、图像质量参差不齐、状态多变等问题,无法直接用于分析处理。
由于点云的非结构性和无序性,目前已有的点云分类网络在精度上仍然需要进一步提高.通过考虑局部结构的构建、全局特征聚合和损失函数改进三个方面,构造一个有效的点云分类网络.首先,针对点云的非结构性,通过学习中心点特征与近邻点特征之间的关系,为不规则的近邻点分配不同的权重,以此构建局部结构;然后,使用注意力思想,提出加权平均池化(Weighted average pooling,WAP),通过自注意力方式...
面向多智能体协作的注意力意图与交流学习方法
多智能体 强化学习 意图交流 注意力机制
2024/1/16
对于部分可观测环境下的多智能体交流协作任务,现有研究大多只利用了当前时刻的网络隐藏层信息,限制了信息的来源.研究如何使用团队奖励训练一组独立的策略以及如何提升独立策略的协同表现,提出多智能体注意力意图交流算法(Multi-agent attentional intention and communication,MAAIC),增加了意图信息模块来扩大交流信息的来源,并且改善了交流模式.将智能体历史...
在城市固体废弃物焚烧(Municipal solid waste incineration,MSWI)过程中,烟气含氧量是影响焚烧效果的重要工艺参数.由于固废焚烧过程的复杂性,在实际应用过程中,难以实现烟气含氧量的有效控制.面向城市固废焚烧过程烟气含氧量控制的实际需求,提出一种基于数据驱动的烟气含氧量自适应预测控制方法.首先,采用自适应模糊C均值(Fuzzy C-means,FCM)算法辅助确定径...
异策略深度强化学习中的经验回放研究综述
深度强化学习 异策略 经验回放 人工智能
2024/1/16
作为一种不需要事先获得训练数据的机器学习方法,强化学习(Reinforcement learning,RL)在智能体与环境的不断交互过程中寻找最优策略,是解决序贯决策问题的一种重要方法.通过与深度学习(Deep learning,DL)结合,深度强化学习(Deep reinforcement learning,DRL)同时具备了强大的感知和决策能力,被广泛应用于多个领域来解决复杂的决策问题.异策略...
以GPT为代表的人工智能生成内容(AIGC)技术的创新扩散,深度改变了数字内容供给侧结构,带来了人机共生、共创的数字创意生态重构与话语权再分配。文章以我国28家出版类上市公司2023年半年度报告及2022年年度报告为研究样本,呈现AIGC创新在出版业扩散的路径、出版业采纳智能内容科技的实践与布局,由此进一步洞察在人类创意创作与人工智能生成所构成的新型人机关系中,智能出版如何做好价值判断与文化定位,...