
搜索结果: 31-45 共查到“工学 学习”相关记录1471条 . 查询时间(0.345 秒)

中国科学院软件所在因果图表示学习方面取得进展(图)
神经 网络 理论
2024/6/28
2023年12月29日,中国科学院软件研究所天基综合信息系统重点实验室研究团队的论文Rethinking Causal Relationships Learning in Graph Neural Networks被人工智能领域顶级学术会议Association for the Advancement of Artificial Intelligence(AAAI)接收,共同第一作者为博士生高航、...
中国科学院合肥物质科学研究院专利:基于机器学习的机动车尾气林格曼黑度测量装置及方法
一种基于随机权神经网络的类增量学习与记忆融合方法
连续学习 灾难性遗忘 随机权神经网络 再可塑性启发
2024/1/16
连续学习(Continual learning,CL)多个任务的能力对于通用人工智能的发展至关重要.现有人工神经网络(Artificial neural networks,ANNs)在单一任务上具有出色表现,但在开放环境中依次面对不同任务时非常容易发生灾难性遗忘现象,即联结主义模型在学习新任务时会迅速地忘记旧任务。
基于滚动时域强化学习的智能车辆侧向控制算法
滚动时域 强化学习 智能汽车 侧向控制
2024/1/16
针对智能车辆的高精度侧向控制问题,提出一种基于滚动时域强化学习(Receding horizon reinforcement learning,RHRL)的侧向控制方法.车辆的侧向控制量由前馈和反馈两部分构成,前馈控制量由参考路径的曲率以及动力学模型直接计算得出;而反馈控制量通过采用滚动时域强化学习算法求解最优跟踪控制问题得到。
近些年,联邦学习(Federated learning,FL)由于能够打破数据壁垒,实现孤岛数据价值变现,受到了工业界和学术界的广泛关注.然而,在实际工程应用中,联邦学习存在着数据隐私泄露和模型性能损失的问题.为此,首先对这两个问题进行数学描述与分析.然后,提出一种自适应模型聚合方案,该方案能够设定各参与者的Mini-batch值和自适应调整全局模型聚合间隔,旨在保证模型精度的同时,提高联邦学习训...
机械臂变长度误差跟踪迭代学习控制
迭代学习控制 误差跟踪 变迭代长度 机械臂
2024/1/16
针对任意初始状态下机械臂轨迹跟踪问题,提出一种变长度误差跟踪迭代学习控制(Iterative learning control,ILC)方法.首先,构造不依赖于期望轨迹的双曲余弦型期望误差轨迹,放宽经典迭代学习控制初始状态要求严格一致的条件.由于该误差轨迹只需设置一个常数项,因而能够有效减少计算量,使得期望误差轨迹的设计更为简单.其次,考虑机械臂运行区间随迭代次数变化的问题,构建虚拟误差变量补偿机...
中国科学院南京土壤研究所专利:一种基于特征集成学习的土壤厚度类型预测方法
中国科学院南京土壤研究所 专利 特征集成学习 土壤厚度
2023/12/11
中国科学院南京土壤研究所专利:一种基于特征集成学习的土壤厚度类型预测方法
中国科学院深圳先进技术研究院专利:交互式语言学习系统及交互式语言学习方法
中国石油集团党组传达学习贯彻习近平总书记重要讲话精神和贺信精神
中国石油 中国石油集团 长三角一体化
2023/12/6
2023年12月4日,集团公司召开党组会(扩大),传达学习贯彻2023年11月27日中共中央政治局会议精神,习近平总书记在中共中央政治局第十次集体学习时、在上海和江苏盐城考察时、在深入推进长三角一体化发展座谈会上的重要讲话精神和致第二届全球数字贸易博览会贺信精神。集团公司党组书记、董事长戴厚良主持。
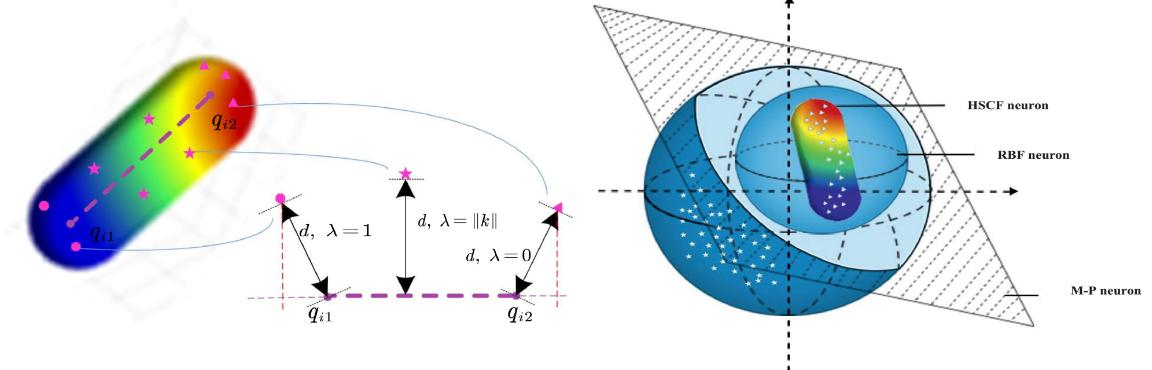
中国科学院半导体所在仿生覆盖式神经元模型及学习方法研究方面取得进展(图)
仿生 神经元模型 网络结构
2024/2/28
人工神经网络是模拟人脑神经活动的重要模式识别工具,受到了众多科学家和学者的关注。然而,近2023年来DNN的改进与优化工作主要集中于网络结构和损失函数的设计,神经元模型的发展一直非常有限。神经生物学和认知神经科学的研究表明,神经元的学习能力是生物神经系统完成学习和记忆任务的重要基础,这些机理可促使我们在神经元设计和优化方面进一步提高DNN的性能。
中国科学院南京土壤研究所专利:基于机器学习的土壤剖面氮素含量高光谱检测及可视化方法
中国科学院合肥物质科学研究院专利:一种基于独立分量集成学习的基因微阵列数据预测方法

中国科学院大气物理研究所自动机器学习提升卫星微波遥感陆地水汽空间分布和精度(图)
自动机器 卫星遥感 水汽空间
2024/1/15
大气水汽是大气圈和水圈的重要组成部分,其时空分布及三相变化与天气演变和气候变化密切相关。卫星遥感是观测全球尺度水汽含量的最重要手段,其中微波被动遥感具有穿透云的能力,可实现全天候全球水汽总量反演,是全球水汽观测系统的重要组成部分。
异策略深度强化学习中的经验回放研究综述
深度强化学习 异策略 经验回放 人工智能
2024/1/16
作为一种不需要事先获得训练数据的机器学习方法,强化学习(Reinforcement learning,RL)在智能体与环境的不断交互过程中寻找最优策略,是解决序贯决策问题的一种重要方法.通过与深度学习(Deep learning,DL)结合,深度强化学习(Deep reinforcement learning,DRL)同时具备了强大的感知和决策能力,被广泛应用于多个领域来解决复杂的决策问题.异策略...